I have sat through enough federal authorization reviews to know how this one goes. Picture the architecture diagram: a single box in the middle labeled "orchestrator," and around it four more boxes, a claims-processing agent, a coding-guideline agent, a clinical-validation agent, and a document-retrieval agent. Clean diagram. Everyone nods along. Then the Authorizing Official (i.e., the person who actually signs the risk acceptance) asks one question. When the orchestrator tells the clinical-validation agent to go pull records from the retrieval agent, which one is inside the authorization boundary, and which one is reaching in from outside it?
Date
6/18/2026
Author
Shailesh Patel
That is the moment the room goes quiet. I have learned to pay attention to that particular silence.
And usually nobody has a clean answer, which is not because the team is unprepared. It is because the question does not have a settled answer yet. Not in the published guidance, not in the System Security Plan (i.e., SSP) template, not in anybody's Authorization to Operate package. We have spent two years arguing about whether federal agencies should buy their AI, build it, or own a dedicated instance of it. That debate is already a step behind the systems. The ones getting stood up in 2026 do all three at once and then wire the pieces together with an orchestrator. And the moment you do that, the authorization boundary stops being a line you draw on a diagram and turns into a question about behavior.
That is what this post is about. Let me walk through it.
The decision everyone frames with one column too few
For two years the federal AI sourcing decision has been framed as a choice among three options. You buy a commercial capability and inherit its authorization posture. You build your own and own every control yourself. Or you take a dedicated instance of someone else's model and land somewhere in between. It is a useful frame. It maps cleanly onto how contracting officers think, how ATO packages get scoped, and how risk gets assigned. I have used it on my own programs.
It is also one column short.
The systems agencies are actually deploying this year do not pick one of the three. They pick all three and then connect them. A commercial model handles general reasoning (i.e., buy). A model fine-tuned on agency data handles the domain-specific work (i.e., build). A dedicated retrieval service sits on the agency's own records (i.e., own). And an orchestrator in the middle decides which one to call, in what order, with what context, to satisfy a single request. That orchestration layer is the part the three-option frame has no word for. So let me give it one. Orchestrate.
Extending the scoping matrix
The sharpest published version of the buy/build/own decision I have come across is Aquia's scoping matrix. It lays out the three scenarios and walks through what each one means for data, control, and authorization. It is good work, and if you have not read it, you should. What I want to do here is extend it, because the matrix stops right at the edge of the orchestration problem, and the orchestration problem is exactly where federal AI is heading.
So add a fourth column. Call it Orchestrate. Then run the same rows you would run for the other three and watch what happens to each one.
Data. In buy, build, or own, you can point at where the data lives and who governs it. Under orchestration, a single request might touch commercial inference, agency-tuned inference, and an internal record store inside of four seconds. The data boundary is no longer a place. It is a path, and the path changes from one request to the next.
Control. In the three classic options, control is a property of the component. You either operate it or you do not. Under orchestration, control becomes a property of the interaction. You may fully control the retrieval agent and not control the commercial model that just instructed it to run a query. Who is accountable for that query?
Authorization. This is the row that breaks. In buy/build/own, the authorization boundary is a set of components you can enumerate and draw a line around. Under orchestration, the behavior that matters most (i.e., one agent deciding on its own to invoke another) is produced at runtime, not at design time. You cannot draw a line around a decision that has not happened yet.
That last one is not a paperwork problem. It is an architecture problem wearing a paperwork costume.
Where the boundary actually breaks
An authorization boundary, in the way FISMA and the SSP use the term, assumes you can describe the system. You enumerate the components, the data flows, and the trust relationships, and then you draw a line around the set. NIST's AI Risk Management Framework (i.e., the AI RMF) gives you four functions to reason about all of this (Govern, Map, Measure, and Manage), and the Map function specifically asks you to establish context and characterize the system. Fine. But how do you Map a system whose behavior is produced when one agent decides, at runtime, to call another one?
Here is the uncomfortable part. When the orchestrator hands a task to the clinical-validation agent, and that agent decides on its own that it needs the retrieval agent to finish the job, the interaction that just happened was not in your code. It emerged from the interaction of two models. You did not author it. You cannot fully enumerate it in advance. And your SSP, as currently written, has no vocabulary for it.
The OWASP Agentic Security Initiative has started naming these failure modes, and the names are worth knowing because they map almost one-to-one onto authorization-boundary questions. Three of them matter here.
ASI07, Insecure Inter-Agent Communication. When agents talk to each other, that channel is an attack surface and an audit gap at the same time. If you cannot see the agent-to-agent traffic, you cannot authorize it, and you certainly cannot monitor it.
ASI08, Cascading Failures. One agent returns a bad result, the next agent treats it as ground truth, and the error propagates through the chain faster than any human-in-the-loop can catch it. The boundary has to account for blast radius, not just access.
ASI10, Rogue Agents. An agent behaves outside its intended scope, whether through compromise, drift, or a prompt it should never have honored. In a single-agent system that is contained. In an orchestrated system, a rogue agent has a phone book of other agents it can call.
Read those three again and notice what they have in common. None of them is about a component being insecure. All of them are about the relationships between components. That is the shift. The boundary is no longer around the boxes. It is around the arrows.
Two patterns that actually work
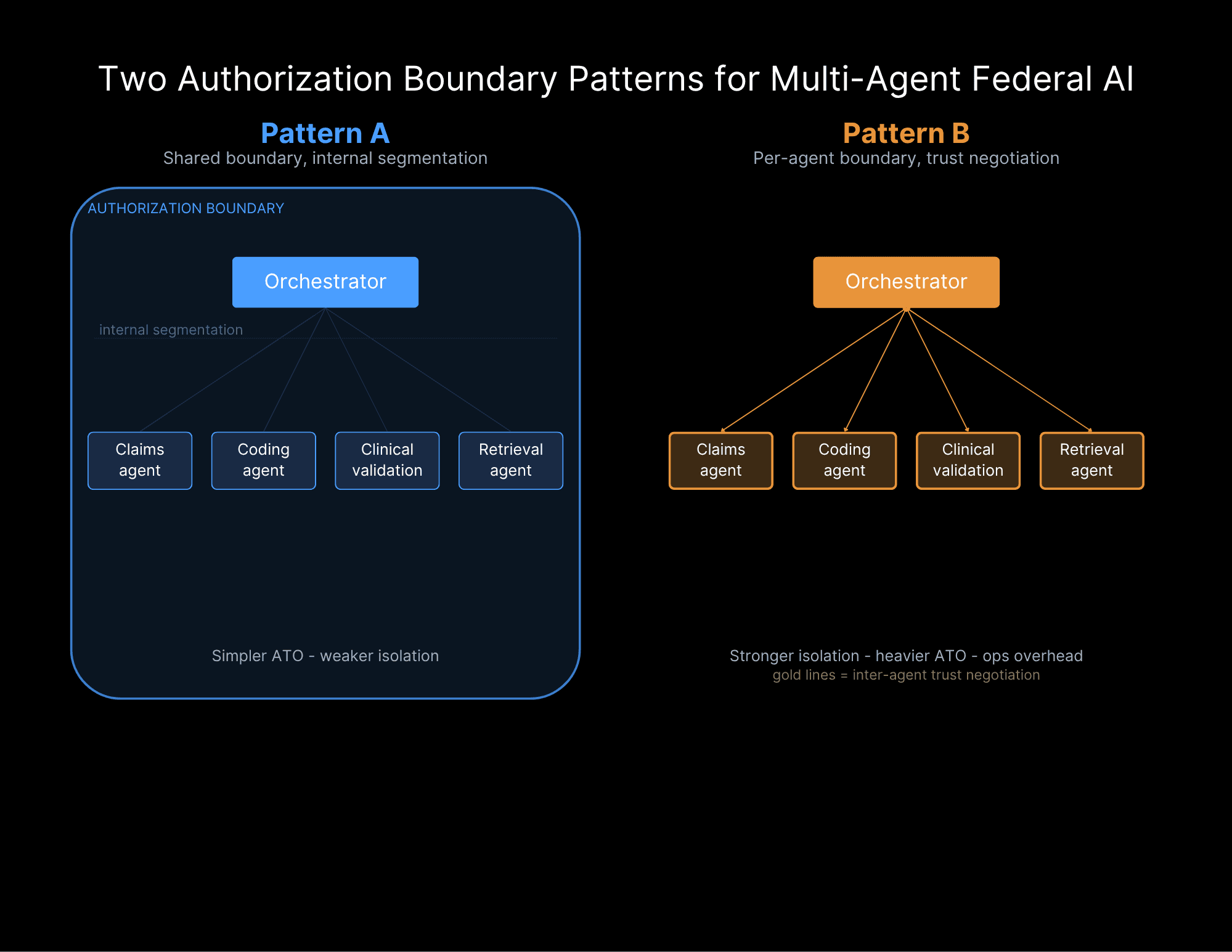
So how do you draw a boundary around a system like this? I have seen two patterns hold up in practice, and they sit at opposite ends of a trade-off.
Pattern A is a shared authorization boundary with internal segmentation. You put the orchestrator and all of its agents inside one boundary and segment internally, the way you would segment a network inside a single enclave. The ATO is simpler because there is one boundary to authorize. The cost is isolation: if one agent goes rogue (i.e., ASI10), it is already inside the boundary with everything else, and your internal segmentation is the only thing standing between a bad agent and the rest of the system.
Pattern B is a per-agent authorization boundary with inter-agent trust negotiation. Each agent gets its own boundary, and when one agent wants to call another, that call crosses a boundary and has to be negotiated and logged like any other cross-boundary request. The isolation is far stronger, and a rogue agent is contained at its own edge. The cost is overhead: more boundaries to authorize, more documentation, more runtime negotiation, and a heavier operational load on the team that has to run it.
How do you choose? The cleanest rule I have found is this: let classification and trust domains decide. If your agents all operate at the same classification level and inside the same trust domain, Pattern A is usually enough, and the simplicity is worth it. The moment two agents sit at different classification levels or in different trust domains (e.g., a commercial model reaching toward an agent that touches controlled data), you are in Pattern B whether you like the overhead or not. Trying to run a mixed-trust system inside a single shared boundary is how you end up explaining a cross-domain spill to people who do not find architecture diagrams charming.
What the SSP, OSCAL, and the SOC have to catch up on
Whichever pattern you pick, three artifacts and one team have to catch up to it.
The SSP has to describe emergent behavior. You cannot enumerate every possible interaction path, because the whole point of the system is that it decides paths at runtime. So stop trying to list paths. Describe the rules of interaction instead: which agents are permitted to call which other agents, what conditions have to hold for a call to be allowed, and what happens when one is not. You are documenting a policy, not a flowchart.
OSCAL has to represent orchestration. The Open Security Controls Assessment Language (i.e., OSCAL) is built to express components and their relationships in a machine-readable ATO package. Use it for that. Model each agent as a component, and model the allowed invocation relationships explicitly, so the orchestration topology lives inside the authorization package rather than in a slide deck nobody updates after the review.
And the SOC has to watch a new kind of traffic. In a multi-agent system, agent-to-agent calls are the new east-west traffic, and right now most security operations centers are blind to it. That agent-to-agent channel (i.e., ASI07 again) is exactly where insecure communication, cascading failures, and rogue behavior show up first. It should be feeding your continuous monitoring evidence, not sitting in an application log nobody reads.
What I would do first
If you are a federal CTO standing one of these up, here is the thing I would do before the architecture diagram, before the vendor selection, before any of it. Write down, in one paragraph, which agents are allowed to call which other agents, and what has to be true for a call to be allowed.
That is it. That one paragraph is your authorization boundary in plain language, and everything downstream (the pattern choice, the SSP wording, the OSCAL model, the SOC rules) falls out of it. Most teams I have watched skip this and try to reverse-engineer the boundary from a finished architecture months later, usually the week before an assessment. That is backwards, and it is expensive, and it is how you end up in a quiet room with an Authorizing Official asking a question you cannot answer.
In the first two posts in this series I argued that where AI runs is never as settled as the diagram makes it look, first at the level of the silicon and the supply chain, then at the level of where inference actually happens. This is the same story one layer up. The thing that looks settled on the slide (a tidy box labeled "orchestrator") is the thing nobody has actually authorized.