Let me describe a meeting I sat through earlier this year. A health system CTO was presenting the AI roadmap for a network of rural hospitals spread across three states. The plan called for AI-assisted radiology reads at point of care, real-time patient monitoring with anomaly detection, and telehealth diagnostics that could run during virtual visits without buffering or dropout. The architecture was straightforward: inference calls to a cloud API, results back to the clinician in under two seconds. The projected API cost for year one, assuming moderate adoption across 14 facilities, was $4.2 million. The room went quiet. Then someone asked what happens when the clinic in rural Appalachia loses its broadband connection for three hours on a Tuesday afternoon and the radiologist is mid-read. Nobody had a good answer.
Date
5/27/2026
Author
Shailesh Patel
Stop and think about that for a moment. We have built an entire AI infrastructure conversation around training clusters, GPU counts, and data center cooling, and that conversation is necessary but dangerously incomplete. The center of gravity in AI is shifting. Training gets the headlines. Inference pays the bills. And for a growing class of applications, particularly in healthcare, the economics of cloud inference do not work. Not at the edge. Not at scale. Not when lives depend on it.
The Numbers Have Already Shifted
The ratio of training to inference compute has inverted faster than most people realize. According to Deloitte, inference workloads account for roughly two-thirds of all AI compute in 2026, up from one-third in 2023 and half in 2025. Inference spending in AI cloud infrastructure hit $20.6 billion in 2026, representing 55% of the $37.5 billion total. That is the first year inference spending exceeded training spending. The crossover happened, and most infrastructure conversations have not caught up.
Let me put this in perspective. The hyperscalers are spending somewhere north of $400 billion on AI data center capital expenditure in 2026. More than half of that is going toward chips, and an increasing share of those chips are doing inference, not training. The edge AI market, which barely registered five years ago, was valued at $24.9 billion in 2025 and is projected to reach $118.7 billion by 2033 at a 21.7% compound annual growth rate. The growth rate alone tells you where the demand signal is coming from. It is not coming from bigger training runs. It is coming from the hundreds of thousands of deployment points where inference must happen close to the data, close to the patient, close to the decision.
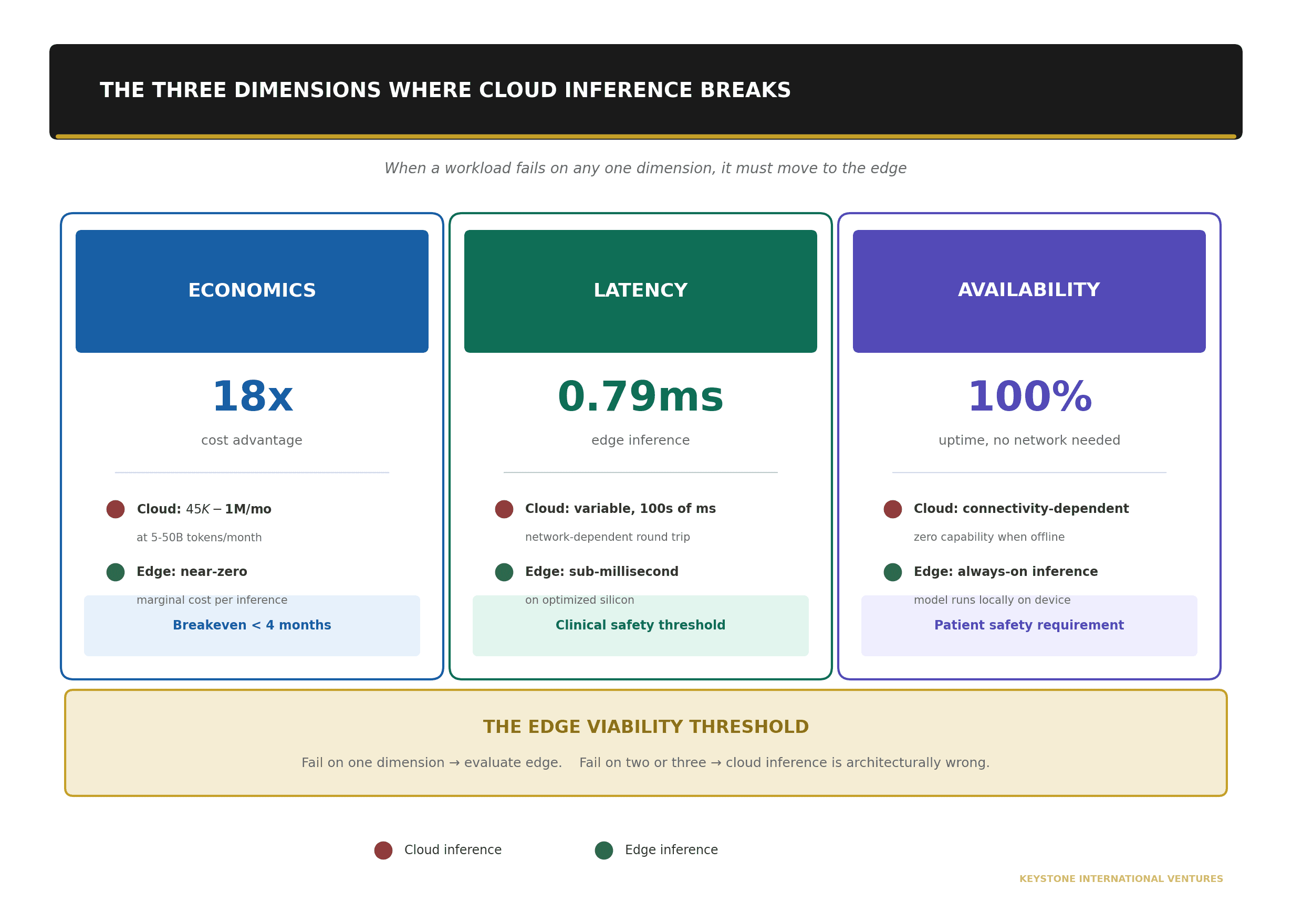
The Three Dimensions Where Cloud Inference Breaks
I find it useful to think about edge viability across three dimensions. When a workload fails on any one of these three, it must move to the edge. When it fails on two or three simultaneously, cloud inference is not just suboptimal. It is architecturally wrong.
The first dimension is economics. The first dimension is economics. Cloud inference is priced per token or per API call. At low volume, the pricing looks reasonable. At scale, it does not. Organizations processing 5 to 50 billion tokens per month face API costs of $45,000 to over $1 million monthly. On-premises inference hardware, by contrast, delivers up to an 18x cost advantage per million tokens compared to cloud APIs, with breakeven in under four months for high-utilization workloads. The marginal cost of an additional inference on owned hardware approaches zero. The marginal cost on a cloud API never does. For a health system running continuous inference across 14 facilities, 24 hours a day, 365 days a year, the cloud pricing model is a structural trap.
The second dimension is latency. The second dimension is latency. In clinical settings, inference delays of even a few hundred milliseconds can degrade performance or compromise patient safety. A clinician performing cardiac ultrasound needs real-time image formation and consistent frame rates to visualize a beating heart and guide decisions as physiology changes from beat to beat. A round trip to a cloud API, even on a good connection, introduces latency that is variable, unpredictable, and subject to network congestion. Edge inference on optimized silicon can deliver sub-millisecond results. Recent benchmarks show lightweight convolutional architectures achieving inference in 0.79 milliseconds on edge hardware. That is not a marginal improvement over cloud round-trip times. It is a different category of performance.
The third dimension is availability. The third dimension is availability. Cloud inference requires connectivity. Connectivity is not a constant. It is a variable, and in many deployment environments, it is an unreliable one. Rural hospitals operate on broadband connections that drop. Mobile clinics operate on cellular networks that degrade. Disaster response units operate in environments where connectivity may not exist at all. When the connection goes down and the model is in the cloud, the AI capability disappears entirely. Edge inference that runs locally on the device does not have this failure mode. The model is present. The compute is present. The inference happens regardless of network state. For healthcare applications where availability is not a feature but a patient safety requirement, this is not a nice-to-have architecture decision. It is a clinical one.
Healthcare Is the Proving Ground
I use healthcare as the anchor for this argument because it is where all three dimensions converge with the highest stakes. But the pattern applies broadly.
Consider three scenarios that are not hypothetical. They are in deployment or in active pilot across U.S. health systems right now.
The first is medical imaging at point of care. A rural hospital in a Critical Access designation (i.e., 25 beds or fewer, more than 35 miles from the nearest hospital) receives a chest X-ray that needs an AI-assisted read. The radiologist is 200 miles away. If the inference runs in the cloud, the image must be uploaded (i.e., bandwidth-dependent), processed (i.e., latency-dependent), and the result returned (i.e., connectivity-dependent). If the inference runs on an edge device co-located with the imaging equipment, the read happens in milliseconds regardless of network state. The clinical workflow does not break when the internet does.
The second is real-time patient monitoring. Continuous inference on vital signs (i.e., heart rate variability, SpO2 trends, respiratory patterns) for anomaly detection and early warning. A cloud-based architecture for this workload means streaming physiological data continuously to an external API. The bandwidth requirement alone is prohibitive when multiplied across dozens or hundreds of monitored patients per facility. Edge inference processes the signal locally and transmits only event-driven alerts, reducing bandwidth consumption by as much as 62% compared to cloud round-trip architectures while improving detection latency from seconds to milliseconds.
The third is telehealth diagnostics. During a virtual visit, an AI model assists with differential diagnosis based on the patient’s history, current symptoms, and visual assessment. Cloud inference introduces jitter and latency that degrade the video consultation itself. Edge computing has been shown to reduce telehealth jitter by up to 35% and improve connection stability, which is particularly impactful in rural settings where reliable internet remains a persistent challenge. The AI capability and the consultation quality improve together when the compute moves to the edge.
The Silicon Mismatch Problem
Here is the part of the conversation that most infrastructure discussions skip entirely. The silicon that dominates AI inference today was not designed for inference. It was designed for training.
A data center GPU built for training carries a thermal design power of 700 watts or more. The latest generation accelerators push past 1,000 watts per chip. These are extraordinary machines, optimized for the massive parallelism that training requires. But inference is a different workload. Inference is sequential, latency-sensitive, and repetitive. It does not need the same memory bandwidth or the same floating-point throughput. What it needs is performance per watt, because the deployment environment is not a climate-controlled data center with liquid cooling and 300-kilowatt rack capacity. The deployment environment is a 50-watt enclosure in a hospital imaging suite, or a 15-watt module in a patient monitoring device, or a battery-powered unit in a mobile clinic.
When you deploy a training-optimized chip for inference workloads, you pay a power penalty for capabilities you do not use. You pay a thermal penalty for a design envelope you cannot accommodate. And you pay an economic penalty because the chip’s cost structure reflects its training capabilities, not its inference efficiency.
The distinction that matters is between inference-first silicon architectures (i.e., chips designed from the ground up for low-power, high-throughput inference at the edge) and training architectures repurposed for inference (i.e., data center GPUs with their power scaled down or their capabilities artificially constrained to fit an edge form factor). The former is where the real innovation is happening. The latter is where most of the current deployment base sits. That mismatch is a structural problem, and it is one of the primary reasons edge inference has been slower to scale than the demand signal would suggest.
The Metric That Matters
If I could change one thing about how the industry benchmarks AI hardware, it would be this: stop leading with FLOPs. FLOPs measure peak theoretical throughput. They are a training metric. For inference, particularly at the edge, the metric that determines economic viability is inferences per watt, or for language models, tokens per watt.
This is not an academic distinction. It is the difference between an AI application that is economically viable at a 200-bed rural hospital and one that is not. A model that delivers 1,000 inferences per watt on a 15-watt edge device gives you 15,000 inferences per second within the thermal envelope. A model that delivers 100 inferences per watt on the same power budget gives you 1,500. Same power. Same thermal constraint. Same hardware cost. Ten times the throughput gap. That gap determines whether the radiology assist is real-time or batch, whether the patient monitor runs continuously or samples intermittently, whether the telehealth diagnostic works in the exam room or only in the IT department’s lab.
MLPerf, the industry’s standard inference benchmark suite, has made progress here. The MLPerf Power framework now standardizes energy efficiency measurement from microwatts to megawatts across data center, edge, mobile, and IoT deployments. But adoption of power-normalized benchmarking in procurement decisions remains limited. Most RFPs still spec FLOPs. Most vendor comparisons still lead with peak throughput. The buyers who understand that inferences per watt is the real constraint are the ones whose edge deployments work.
What This Means for CTOs
If you are building an AI capability that must run outside a data center, whether that is in a hospital, a clinic, a field operation, or any environment where power, connectivity, and physical space are constrained, I am suggesting three things worth thinking about.
First, model your inference economics separately from your training economics. Model your inference economics separately from your training economics. They are different workloads with different cost structures, and the cloud pricing model that works for training does not automatically work for inference at scale. Run the total cost of ownership calculation for your specific volume, latency, and availability requirements. For sustained, high-volume inference, the math almost always favors edge or on-premises deployment.
Second, start evaluating silicon on inferences per watt, not FLOPs. Start evaluating silicon on inferences per watt, not FLOPs. Ask your vendors for power-normalized performance data. If they cannot provide it, that tells you something about whether their hardware was designed for your workload or adapted from someone else’s.
Third, architect for the connectivity you have, not the connectivity you wish you had. Architect for the connectivity you have, not the connectivity you wish you had. If your deployment environment includes locations where broadband is intermittent, cellular coverage is variable, or network outages are measured in hours rather than minutes, then cloud-dependent inference is a single point of failure in your AI capability. Edge inference is not a backup plan. It is the primary architecture.
Training built the models. Inference is where they create value. And for a growing share of the applications that matter most, that value must be created at the edge, on silicon designed for the job, within thermal and power envelopes that the data center never had to think about.
The edge is not a secondary deployment target. It is the real AI infrastructure story. We should start building like it.
This is the second in a series on AI infrastructure, federal AI governance, and delivery methodology.
Next: “The Buy / Build / Own / Orchestrate Decision for Federal AI” (June 9, 2026)
Shailesh Patel is CTO of Keystone International Ventures and a SAFe Program Consultant (SPC). He writes about the intersection of AI architecture, federal technology, and the delivery frameworks that connect them.